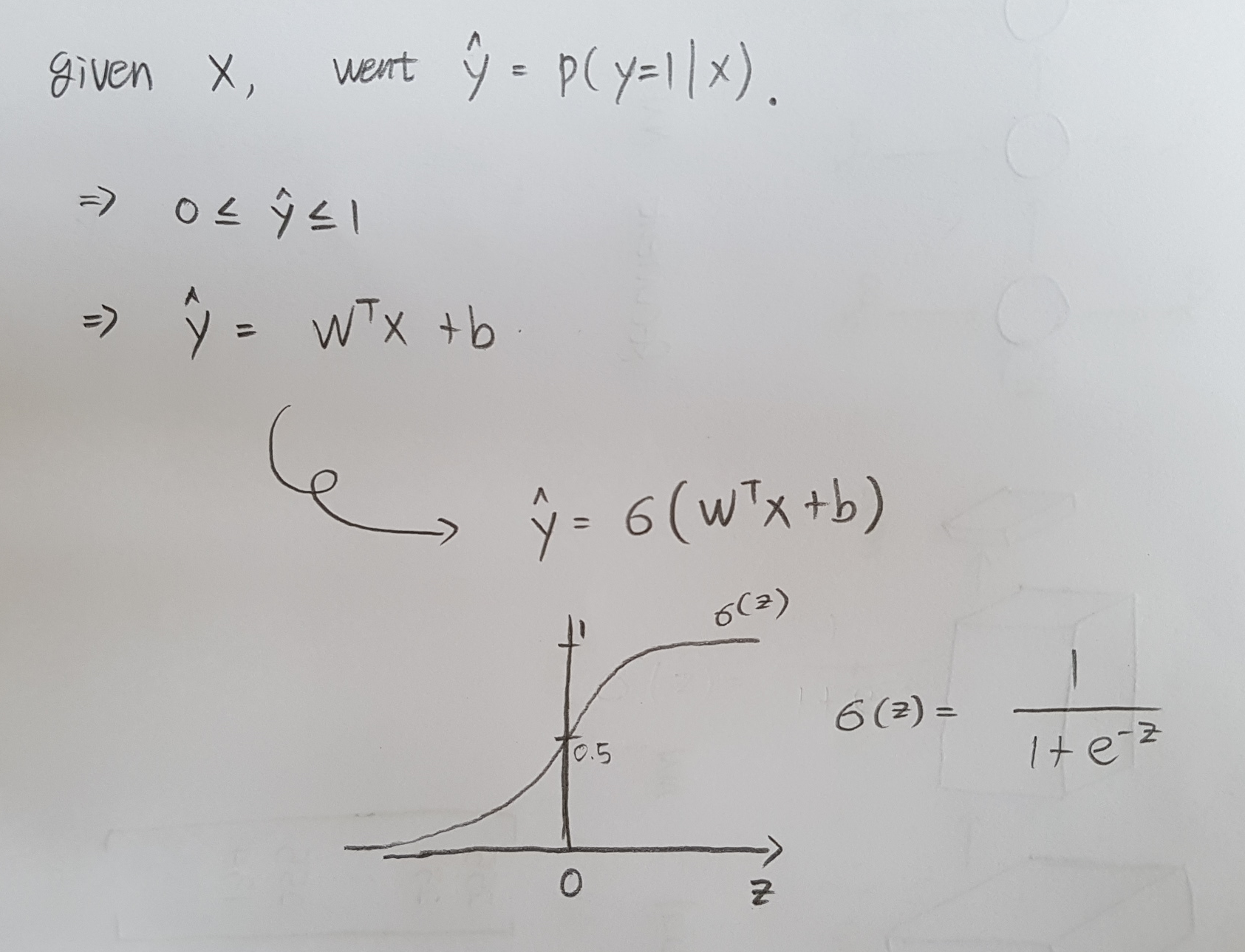This note is based on Coursera course by Andrew ng.
(It is just study note for me. It could be copied or awkward sometimes for sentence anything, because i am not native. But, i want to learn Deep Learning on English. So, everything will be bettter and better :))
Logistic regression is an algorithm for binary classification. So, let's start by setting up the problem. Here's an example of a binary classification problem. I have an input of an image, like below, and want to output a label to recognize this image as either being a cat, in which case you output 1, or not-cat in which case you output 0, and I am going to use to denote the output label.

Let's look at how an image is represented in a computer. To store an image your computer, stores three separate matrices corresponding to the red, green, and blue color channels of this image. To turn these pixel values into an input feature vector x, what i am going to do is unroll all of these pixel values into an input feature vector x. Which in this case, I have 12,288 elements in vector x.

Training sets will comprise lower-case m training examples. And the training sets will be written like below, which is the input(x) and output(y).

To output all of the training examples into a more compact notation, I'm going to define a matrix, X and Y.

X is an dimensional vector and Y hat is the probability of the change. Y is equal to one given the input features X. So given that the parameters of logistic regression will be W which is also an X dimensional vector, together with b which is just a real number. To generate the output Y hat, I would be to have W transpose X plus B, kind of a linear function of the input X. However, it is not a good algorithm for binary classification because I want to Y hat to be the chance that Y is equal to one. So Y hat should really be between zero and one, and it's difficult to enforce that because W transpose X plus B can be much bigger than on or it can even be negative, which doesn't make sense for probability.

So in logistic regression, my output is instead going tobe Y hat equals the sigmoid function applied to this quantity. And sigmoid function looks like below. If Z is very large, then E to negative Z will be close to zero. Conversely, if Z is very small, or it is a very large negative number, sigmoid of Z goes very close to zero. So when you implement logistic regression, your job is to try to learn parameters W and B so that Y hat becomes a good estimate of the chance of Y being equal to one.