This note is based on Coursera course by Andrew ng.
(It is just study note for me. It could be copied or awkward sometimes for sentence anything, because i am not native. But, i want to learn Deep Learning on English. So, everything will be bettter and better :))
INTRO
One of the things that might help spead up learning algorithm is slowly reduce learning rate over time.
Let's start with an example of why we might want to implement learning rate decay.
MAIN
WHAT
Suppose we are implementing mini-batch gradient descent, then as iteration, steps will be a little bit nosiy. And it will tend towards this minimum over there, but it won't exactly converge. But algorithm might just end up wandering around, and never converge. This is because we are using some fixed value for alpha.
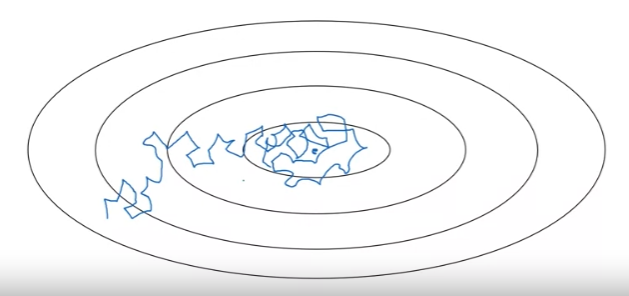
But if we were to slowly reduce learning rate alpha, then during the initial phases, while learning rate alpha is still large, we can still have relatively fast learning. But then as alpha gets smaller, the steps we take will be slower and smaller. And, we end up oscillating in a tighter region this minimum rather than wandering far away .
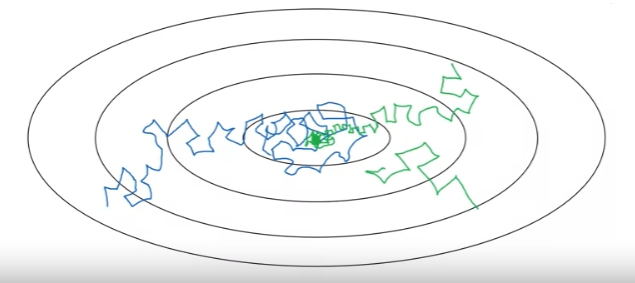
HOW
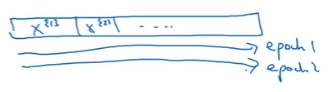
Recall 1 epoch is 1 pass through the data.
And the equation is :
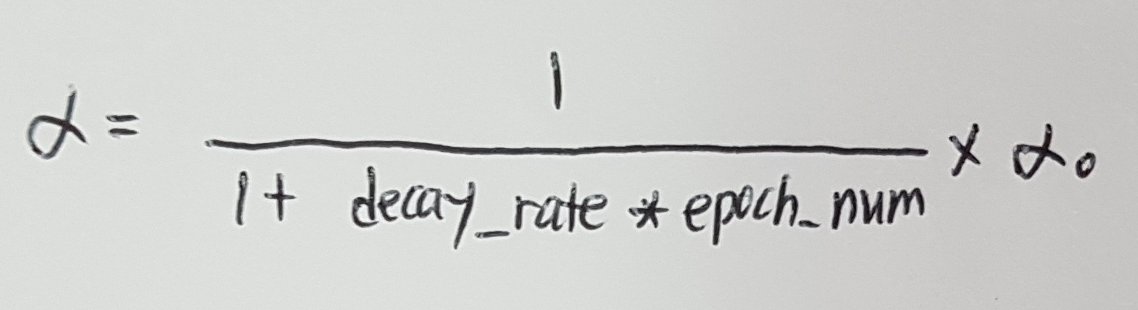
For example :
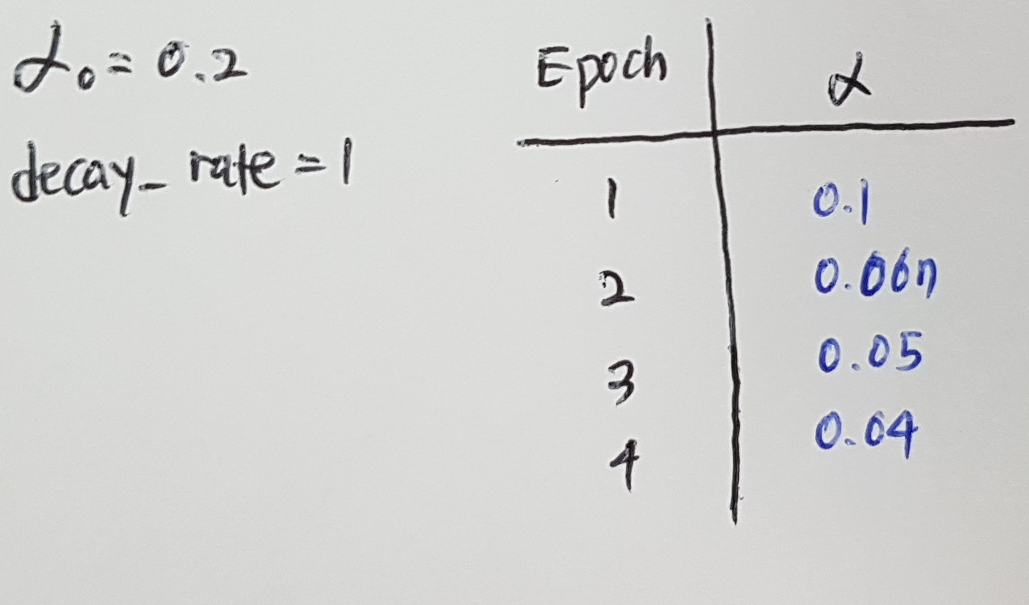
CONCLUSION