This note is based on Coursera course by Andrew ng.
(It is just study note for me. It could be copied or awkward sometimes for sentence anything, because i am not native. But, i want to learn Deep Learning on English. So, everything will be bettter and better :))
INTRO
What are Bias and Variance? And you might have heard this thing called bias-variance trade-off. Let's see what this means.
MAIN
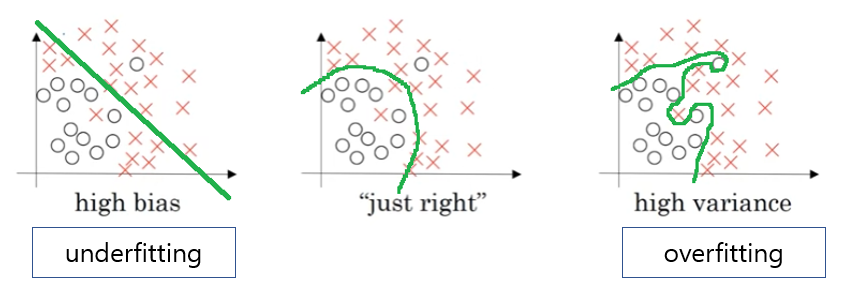
Let's see the data set that looks like this. If we draw staight line at right dataset. This is not a very good fit to the data. So, this is class of a high bias, what we say that is underfitting the data. On the opposite end, if we fit an incredibly complex classifier, we might fit the data perfectly, but that doesn't look like a great fit either. And there might be some classifier in between, with a medium level of compexity.
So, in a 2D example like this, we can plot the data and visualize bias and variance. But in high dimensional problems, we cannot plot the data and visualize division boundry. Instead, we are gonna use train-set-error and dev-set-error. Let's say we are recognizing cats in pictures. And errors show up like below.
Train set error: 1% 15% 15% 0.5%
Dev set error: 11% 16% 30% 1%
high variance high bias high bias low bias
high variance low variance
(base error 0%, human)
1. We are doing well on the training set, but we are doing relatively poorly on the development set. So, this looks like we might have overfit the training set, that somehow we are not generalizing to this whole dev set. Then, we would say this has high variance.
2. In this case, assuming that humans achieve roughly 0% error. Then, it looks like the algorithm is not even doing very well on the training set. And, this is underfitting and this algorithm has high bias.
3. We would diagnose this algorithm as having high bias, because it is not doing well on the training set, and high variance.
4. This has low bias and low variance.
In shortly, by looking at out training set error, we can get a sense of how well we are fitting. And that tells us if we have a bias problem. And then looking at how much higher our error goes from training-set to dev-set, it should give a sense of how bad is the variance problem.
By the way, what is high bias + high variance? This classifier is mostly linear and therefore underfits the data, but then it is actually overfitting parts of the data as well. So, it has both high bias and high variance.

CONCLUSION
We have seen how by looking at our algorithm's error on the training set and on the dev set. We can try to diagnose whether it has problems of high bias or high variance, or maybe both, or maybe neither.